
In unserer digitalen Welt müssen heute immer mehr und immer komplexere Daten in immer größerer Geschwindigkeit verarbeitet werden. Dabei stoßen die „klassischen“ Systeme immer öfter an physikalische Grenzen.
Bei der klassischen Datenverarbeitung werden die Daten durch einen ETL-Prozess in eine Datenbank gespeichert. Dieser Prozess wird oft in mehreren Schichten (Layers) durchgeführt. Daten landen in einem Data-Warehouse, also einer Datenbank, deren Schemata vorher fest definiert ist („Schema-on-Write). Wir sind bereits im Beitrag „Eintauchen in den Data Lake“ auf den grundlegenden Aufbau und Unterschied von Data Warehouses und Data Lakes eingegangen. Kurz zur Auffrischung: „Schema-on-Write“ bedeutet, dass das Datenmodell vorher definiert ist und die Daten, die in das Datenmodel importiert werden, jedes Mal überprüft werden müssen, ob Sie in das Schema passen (Datentyp, Länge, Beziehung zwischen Tabellen usw.). Deswegen „Schema-on-Write“.
Bei kleinen bis mittleren Datenmengen funktioniert dieses Prinzip sehr gut und durch das „Schema-on-Write“ ist gewährleistet, dass die richtige Daten im Data-Warehouse gespeichert werden.
Speicherarten: Schema-on-Write vs Schema-on-Read
Wenn die Datenmenge sehr groß ist und Daten sich mit hoher Geschwindigkeit ändern (Big Data), stoßt das Prinzip „Schema-on-Write“ jedoch an seine Grenzen. Bei jedem Schreibvorgang muss erst überprüft werden, ob die Daten in das Daten-Modell passen. Ab einer bestimmten Geschwindigkeit kommt es dabei zu einem „Stau“ beim Schreibprozess.
Daher arbeiten Data Lakes mit dem „Schema-on-Read“. Dabei werden Daten beim Schreibprozess in das System nicht überprüft, sondern einfach mit großer Geschwindigkeit in das System reingeschrieben. Erst beim Lesen wird das Schema für die Daten definiert, deswegen „Schema-on Read“. Das bringt enorme Performance-Steigerung bei der Datenverarbeitung. Nachdem die Daten in das System (den Data Lake) reingeschrieben wurden, werden sie in einem Batch Prozess analysiert (Big Data Batch Processing). In einem Hadoop Cluster heißt dieser Job „Map-Reduce“. Ein „Map-Reduce“ Job kann sehr große Datenmengen in sehr kurze Zeit analysieren, weil sein Hauptfeature darin besteht, den Job auf tausenden Clustern auszuführen und Daten somit parallel zu verarbeiten. So können z.B. Massen an Daten auf einem Datenträger zusammen mit Bewegungsdaten eines Internetportals oder Messdaten von tausenden Sensoren gespeichert und verarbeitet werden.
Doch auch dieses Prinzip stößt in der Big Data Welt an seine Grenzen. Es funktioniert nur so lange gut, wie die Datenmenge endlich ist.
Wenn es aber um Datenmengen geht, die nicht nur sehr groß sind, sondern sich auch schnell in der Zeit ändert, muss ein anderes Prinzip der Datenverarbeitung implementiert werden. Daten müssen in Echtzeit analysiert werden. Wir kommen zu „Real Time Analytics“.
Real Time Analytics als Lösung der steigenden Herausforderungen
Viele von uns nutzen eine Navigation, um von A nach B zu kommen. Die Verkehrssituation wird heutzutage von verschiedenen Systemen überwacht, auf die wir über unsere Navi-App Zugriff haben. Die Geschwindigkeit der Fahrzeuge wird in Echtzeit verfolgt und wenn sie unter eine bestimmte Grenze fällt – z.B. 5 KM/Std – wird das System einen „zähfließenden Verkehr“ erkennen. Wenn Fahrzeuge z.B. länger als 5 Sekunden stehen, wird „Stau“ gemeldet.
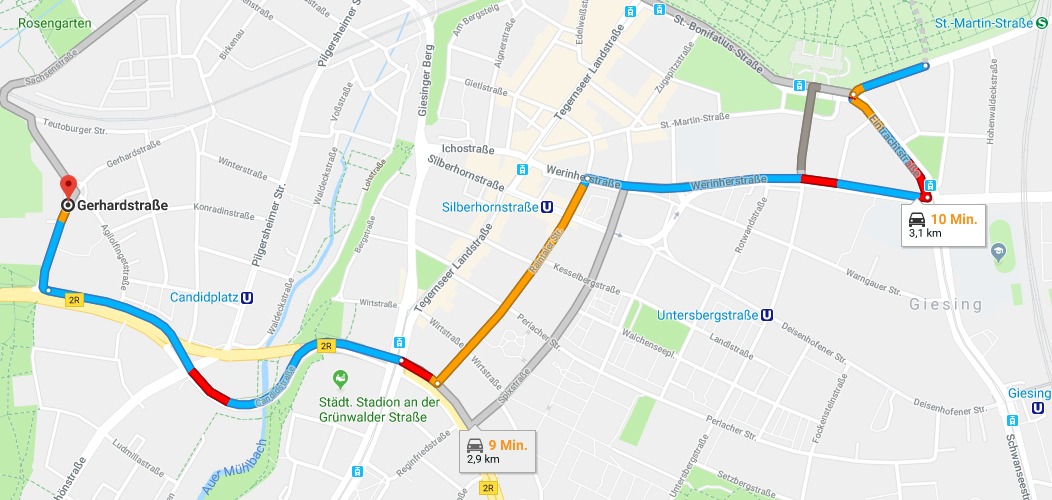
Technisch funktioniert das Ganze so: Daten kommen über ein Tor bzw. einen Hub (Event Hub oder IoT Hub) in das System rein, werden verarbeitet, in einem Dashboard (oder in unserem Beispiel ein Navi) angezeigt und gleichzeitig in einen Data Lake gespeichert.
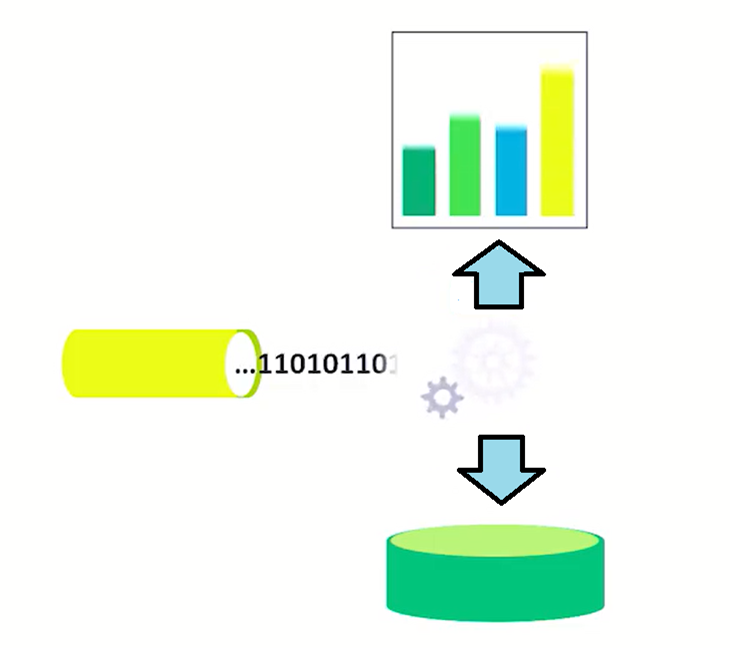
Als Eingangstor (Hub) wird ein Event Hub oder ein IoT Hub verwendet. Die Hubs unterscheiden sich dabei in verschiedenen Punkten:
- Event Hub Ein Event Hub ist eine einfache Variante des Eingangstores (Hub) für die Daten.
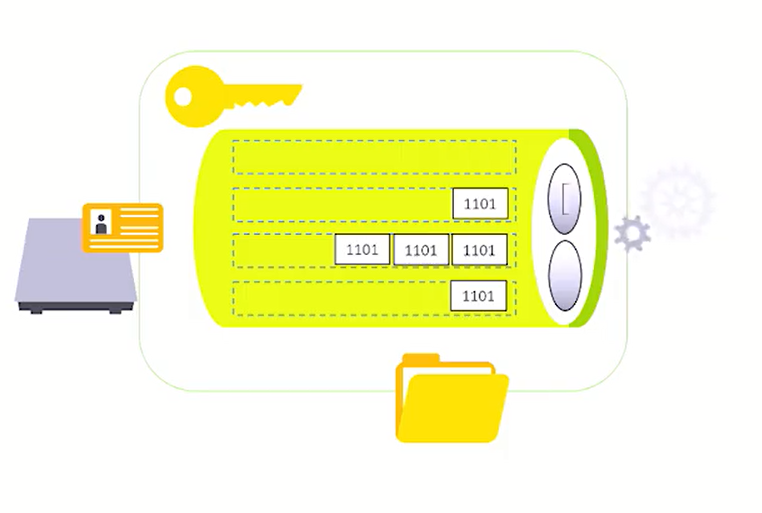
Ein Event Hub hat folgende Eigenschaften:
- Adresse (Beispiel: Endpoint= sb:// …servicebus.windows.net)
- Schlüssel (Beispiel: SharedAccessKey= bHsjekffaslo24….)
- Parallele Verarbeitung (es können mehrere Clients Daten gleichzeitig schicken)
Jeder, der diese Informationen hat (Adresse und Schlüssel), kann die Daten an den Event Hub schicken. Ein Event Hub ist eine Einbahnstraße. Das heißt, die Daten fließen nur vom Client in den Event Hub und nicht umgekehrt. IoT Hub Ein IoT Hub ist eine komplexere Variante des Eingangstores (Hub) für die Daten. Bietet aber mehr Möglichkeiten, höhere Sicherheit und Duplex Datenverkehr.
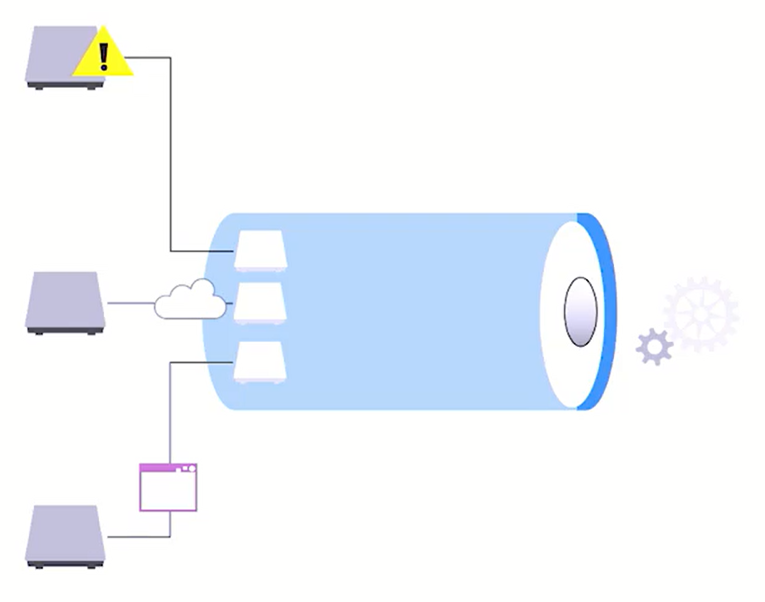
Ein IoT Hub hat folgende Eigenschaften:
- Adresse des IoT Hubs (Beispiel: HostName= …azure.devices.net)
- Adresse des Clients (Beispiel : HostName= …azure.devices.net, DeviceId= ‘MyDeviceName’)
- Schlüssel (SharedAccessKey= bHsjekffaslo24….)
- 1 zu 1 Verbindung. Jeder Client ist fest mit einer IoT Adresse verknüpft. Es kann sich nur ein Client mit einem IoT Hub verbinden, Sie sind zuzusagen verheiratet. Dies führt zu höherer Sicherheit.
- Nicht nur der Client kann die Daten an den IoT Hub schicken, sondern auch umgekehrt (Duplex Datenverkehr). Zum Beispiel es ist möglich, sich mit einem Kühlschrank, der über IoT mit dem Internet verbunden ist, von außen zu verbinden und Daten (z.B. Softwareupdates) an den Kühlschrank zu schicken. Das geht beim Event Hub nicht.
Ein Blick durchs Fenster
Um die Daten nun zu analysieren, muss man einzelne „Portionen“ entnehmen. Wir betrachten sie also immer in einem bestimmten Zeitfenster (Window). So wird z.B. die Durchschnittsgeschwindigkeit von Autos pro Minute gemessen oder die Durchschnittstemperatur pro Stunde.
In vielen Szenarien mit Echtzeit-Daten ist es nötig, Vorgänge für die Daten in temporalen Fenstern durchzuführen. Dieses Stream Analytics Verfahren nennt man „Windowing“. Es gibt mehrere Typen von Windowing.
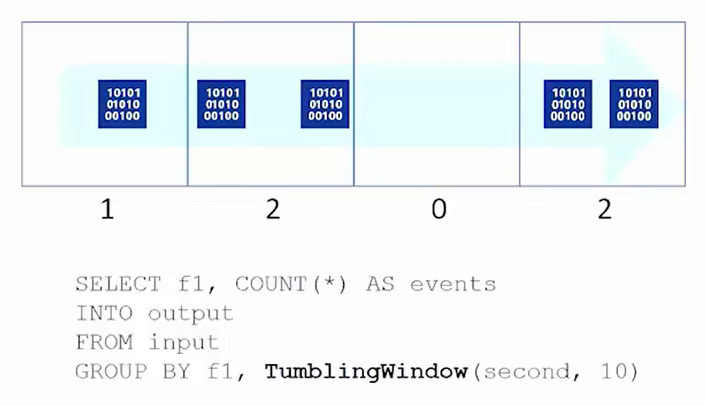
- Tumbling Window (Rollierendes Fenster)Beim „Tumbling Window“ werden Daten in Fenstern von konstanter Länge gemessen. In unserem Beispiel alle 10 Sekunden. Wir haben im ersten Fenster einen Wert, im zweiten zwei Werte, im dritten keinen Wert usw.Die Fenster folgen aufeinander ohne Zeitverzug und ohne Überlappung. Rollierende Fenster werden verwendet, um Daten in einzelne Zeitsegmente zu unterteilen und dafür eine Funktion durchzuführen, siehe Beispiel.
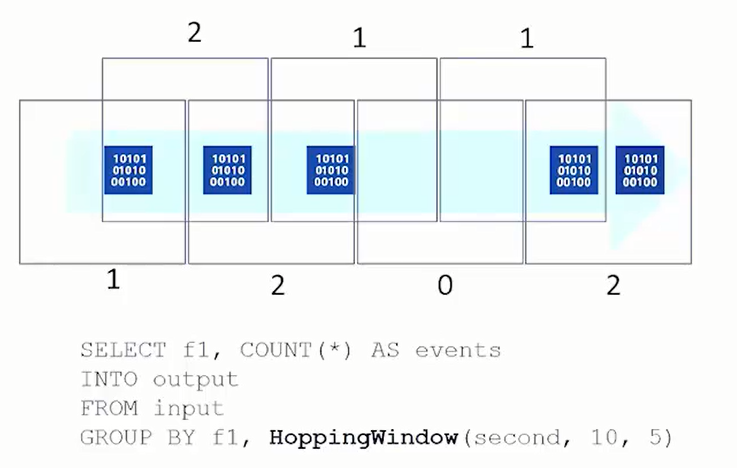
Hopping Window (Springendes Fenster)Beim „Hopping Window“ überschneiden sich die Fenster der Datenanalyse. Im Beispiel werden alle 5 Sekunden Daten von den letzten 10 Sekunden aggregiert. Das heißt, alle 5 Sekunden können wir Daten von den letzten 10 Sekunden darstellen.
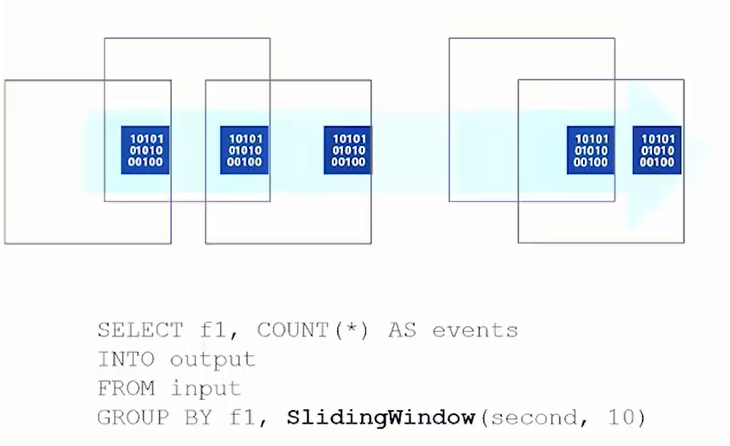
Sliding Window (Schiebefenster)
Daten werden nur dann analysiert, wenn Sie kommen. Wenn keine Daten kommen werden auch keine analysiert. Auch hier können Ereignisse zu mehr als einem Schiebefenster gehören.
In unserem Beispiel werden Daten für 10 Sekunden analysiert, wenn ein Ereignis eintritt.
Real Time Analytics spielt bei verschiedenen Anwendungen eine große Rolle. Neben unserem verwendeten Beispiel der Verkehrsdaten oder Wetteranalyse werden im Geschäftsleben z.B. bei Aktienkursen an der Börse automatisch Kauf-/ Verkaufs Jobs ausgeführt, in Onlineshops können Preise in Real Time angepasst werden oder Werbeanzeigen werden ganz gezielt, abhängig vom gerade gezeigten Verhalten, in Echtzeit angepasst werden.
Fazit
Real Time Analytics hat ein enormes Potential. Der Bedarf, riesige Datenmengen in Echtzeit zu verarbeiten, wird in Zukunft noch weiter steigen. Zahlreiche moderne Techniken bauen auf der Verfügbarkeit der Technologie auf und werden stetig weiterentwickelt. Somit können wir erwarten, dass diese Art der Datenverarbeitung und -analyse stetig weiter an Bedeutung gewinnen wird.




