
Nachdem ich vor einigen Wochen bereits einen allgemeinen Einblick in Machine Learning gegeben habe, werden wir uns heute die technischen Hintergründe ein bisschen näher anschauen. Dabei orientiere ich mich bei der Erklärung an Microsoft Machine Learning bzw. ML Studio, es ist aber allgemein übertragbar.
Noch mal zur Auffrischung: Bei einem klassischen Algorithmus legen Programmierer oder Analysten eine bestimmte Logik fest, die sich im Laufe der Zeit nicht ändert. Die Maschine verarbeitet dann die Daten entsprechend des Schemas. Bei Abweichungen oder unbekannten Konstellationen kann der klassische Algorithmus die Daten nicht verarbeiten und gibt einen Exception-/Ausnahmefehler zurück. Die Beziehungen zwischen Variablen sind fest definiert und ändern sich nicht.
Beim Maschinellen Lernen hingegen kann sich die Logik im Laufe der Zeit anpassen, die Maschinen “lernen” und Künstliche Intelligenz entsteht. Programme und Algorithmen verbessern sich selbst. Beziehungen zwischen den Variablen sind nicht fest, sondern ändern sich im Laufe der Zeit. Auch Algorithmen sind nicht fest definiert, sondern entstehen während des Lernprozesses. Entsprechend geht es bei Machine Learning hauptsächlich um die Mustererkennung und die Erkennung von Beziehungen zwischen den Entitäten.
Im Grunde genommen gibt es zwei hauptsächliche Ansätze: Überwachtes (supervised) Lernen und Unüberwachtes (unsupervised) Lernen. Bei der Künstlichen Intelligenz (KI) werden teilweise aucg beide Ansätze kombiniert.
- Unüberwachtes Lernen
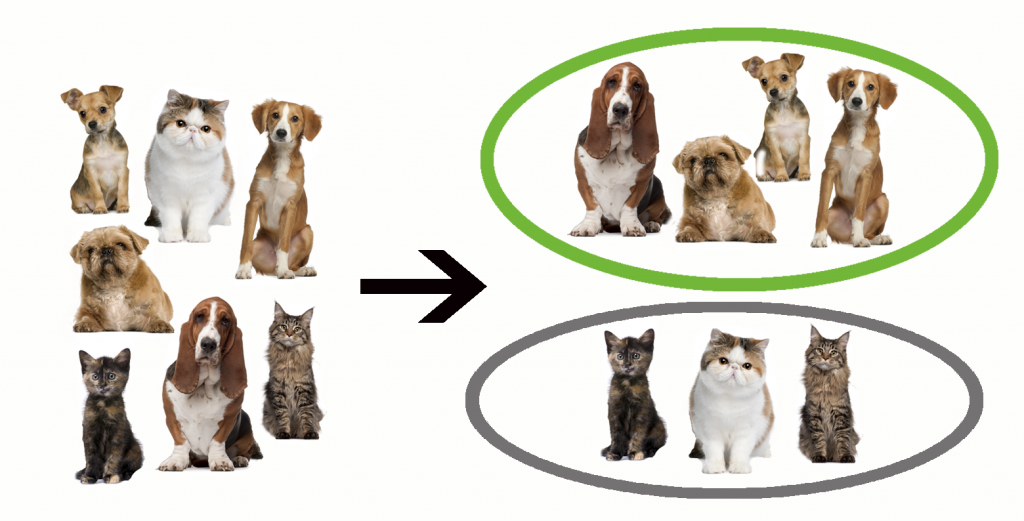
Beim Unüberwachten Lernen weiß das System nicht, was es erkennen soll. Es erkennt Muster und teilt die Daten in Cluster oder Kategorien auf, jedoch ohne zu wissen, um welche Kategorien es sich handelt, bzw. unter welches Label sie fallen.
Wenn es beispielsweise Bilder von Tieren verarbeitet, teilt das System alles was aussieht wie eine Katze oder alles was aussieht wie ein Hund in entsprechende Gruppen ein, ohne diese jedoch so zu benennen, da wir noch nicht definiert haben, was eine Katze und was ein Hund ist. Diese Methode wird angewandt, wenn wir die Daten noch nicht kennen und entsprechend keine Vorgaben machen können.
Innerhalb dieser Methode gibt es zwei Ansätze:
a) Clustering, oft auch K-Means Clustering genannt
Der Machine Learning Algorithmus wird die Bilder in die Kategorien Katzen, Hunde und Pferde aufteilen, obwohl er darauf nicht trainiert wurde und ohne die Kategorien zu kennen.
b) Reduzierung der Dimensionalität (dimensionality reduction)
Das System erkennt durch ein Muster, welche (im Vorfeld definierten) Dimensionen zusammen gehören und reduziert diese. Das steigert die Performance bei der Verarbeitung und Analyse.
- Überwachtes Lernen
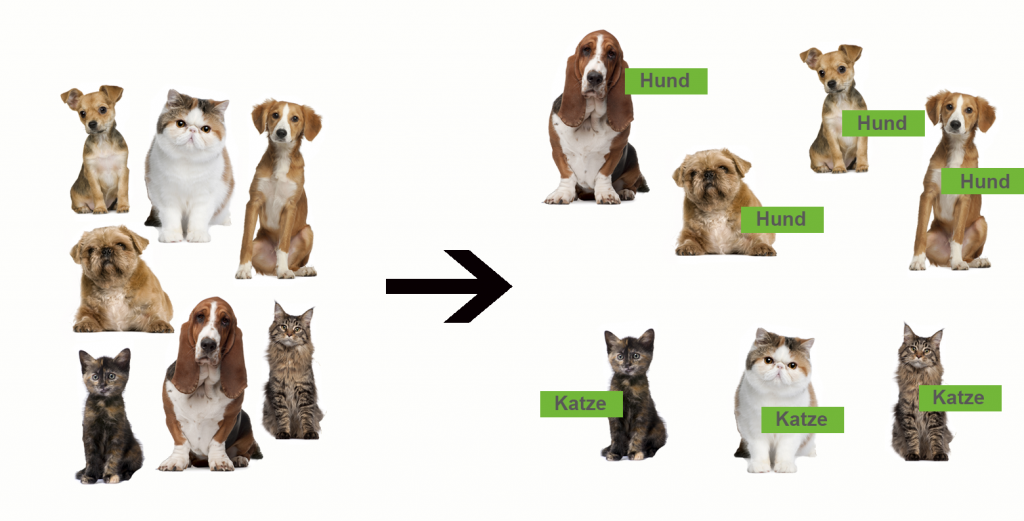
Beim Überwachten Lernen kennen wir eine sogenannte Grundwahrheit (ground truth). Es gibt Training Daten, bei denen wir die Eingangs-Parameter sowie das Ergebnis kennen. Aus den Training Daten werden Modelle erstellt, die zusammen mit den Machine Learning Algorithmen das Ergebnis liefern. Wenn die Modelle erstellt wurden, können wir dem Modell unbekannte Daten liefern und das System berechnet für uns das Ergebnis (Prediction).
Soweit zum Unterschied zwischen unüberwachten und überwachten Lernen als Hintergrund des maschinellen Lernens. In meinem nächsten Beitrag werde ich den Prozess des Machine Learning im Detail vorstellen, so dass wir einen Einblick erhalten, wie eine Maschine letztendlich „lernt“.



