Nachdem wir uns bereits mit den Grundlagen und Beispielen zu Machine Learning sowie den Lerntypen beschäftigt, haben, wollen wir uns heute den Prozess als solches ansehen. Die Prozesskette für einen Machine Learning Prozess – egal ob in Hadoop, AWS, Azure, einer anderen Cloud oder „on Premise“ – kann in den folgenden sechs Schritten abgebildet werden.
1. Datenimport
Bevor wir Daten analysieren und ein Model trainieren, müssen wir die Daten in das System importieren. Machine Learning Studio bietet die Möglichkeit, Daten aus verschiedenen Quellen zu ziehen, wie AZURE Blob Storage, Azure DB, DWH, Hadoop, OData, On Premise SQL Server, aus dem Web (http) und per manueller Eingabe. Daten werden intern in sogenannten Datasets gespeichert und zur weiteren Verarbeitung zu Verfügung gestellt.
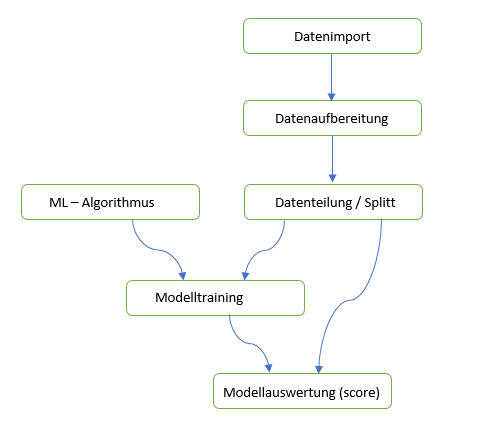
2. Datenaufbereitung (Preprocess)
In diesen Schritt werden Daten für den Machine Learning Algorithmus vorbereitet. In diesem Schritt werden Daten normalisiert, partitioniert, gefiltert oder transformiert. Es können neu berechnete Spalten hinzugefügt werden, eine Datenkonvertierung durchgeführt werden usw.. Wenn die Daten im Quellsystem vorbereitet wurden, ist dieser Schritt nicht zwingend notwendig. Wenn aber z.B. rohe Daten eingelesen werden, können wir in diesem Schritt die notwendigen Aktionen durchführen.
3. Datenaufteilung (Split Data)
Jeder Machine Learning Algorithmus funktioniert so, dass die Daten in Training und Score (Auswertungs-) Daten aufgeteilt werden müssen.
Wie das funktioniert? Wir haben z.B. historische Daten eins Internetportals aus den letzten drei Jahren. Produkte die verkaufte wurden und entsprechende Klassifizierungen z.B. nach Datum, Kunden (Eigenschaften wie Mann, Frau, Vielkäufer, Sparfuchs), Orte und sonstige Daten wie z.B. Wetterdaten. Die Daten werden dann z.B. 70% für Training und 30% für die Auswertung geteilt.
4. Machine Learning Algorithmus
Es existieren zwei unterschiedliche Algorithmus Typen: Klassifikation und Regression.
a. Klassifikation
Dieser Typ des Machine Learning Algorithmus wird dazu verwendet, unbekannte Daten zu klassifizieren, oder zu kategorisieren. Dieser Typ wird oft bei der Bildererkennung oder OCR (Texterkennung) verwendet. Beispielsweise unterteilt das System in Bilder mit Katzen, Hunden oder Personen. Als Ergebnis wir immer ein Ja, oder Nein geliefert. Ist es eine Katze, ist es Buchstabe „A“ usw.
b. Regression
Regression-Algorithmen liefern immer eine Zahl. Zum Beispiel die Temperatur in den nächsten Tagen, Aktienwerte oder die Anzahl der verkauften Produkte. Es gibt viele Regression Algorithmen:
• Lineare Regression
• Bayesian Regression
• Decision Tree/ Forest
• Neural Network Regression
• Poison Regression
5. Modell-Training
Training-Modelle verwenden als Input-Parameter Training Daten und einen ausgewählten Algorithmus, um das Model zu trainieren. Es werden Attribute definiert und das System probiert anschließend, die Zusammenhänge zwischen den Attributen zu erkennen und Ergebnisse zu ermitteln. Ein Beispiel: Mit den Input-Attribute Geschlecht (Mann, Frau), Kaufverhalten (Vielkäufer, Sparfuchs), Ort und Wetterdaten kann das Ergebnis die erwartete Anzahl verkaufter Produkte sein.
6. Modellauswertung (Scorer Model)
Nach dem das Modell trainiert wurde, werden Ergebnisse mit den bereits existierenden Daten verglichen, um die Genauigkeit der Vorhersage des Modells zu bewerten.
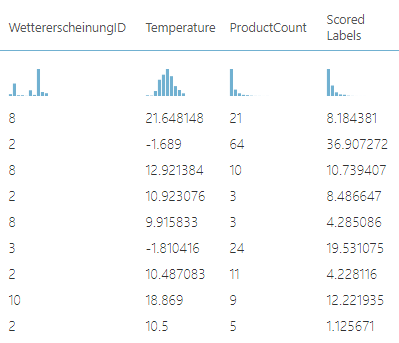
Ein Beispiel des Ausgangs beim Score-Model.
WettererscheinungID, Temperature und ProductCount sind bekannte Parameter (bei bestimmte Temperatur und Wettererscheinug wurde eine bestimmte Anzahl Produkte (ProductCount) verkauft). Scored Labels ist die Zahl, die vom Machine Learning Algorithmus vorhergesagt wurde.
Wenn wir die ProductCount und Scored Labels vergleichen, sehen wir, dass es Unterschiede gibt zwischen dem, was tatsächlich verkauft wurde und dem, was vorhergesagt wurde. Es gibt aber auch gute Treffer.
Die Genauigkeit der Vorhersage ist durch den Machine Learning Algorithmus bestimmt. Manche Algorithmen sind für spezielle Vorhersagen gut oder schlecht geeignet. Es ist auch möglich, das Verhalten der Algorithmen durch verschiedene Parameter zu steuern.
Wie das genau funktioniert, werden wir uns im nächsten Teil anschauen.



